In the last years, always more companies started introducing AI systems impacting their business. Machine Learning is used in e-commerce, advertisement, health, finances, driving, industry, and many other contexts. Besides the big tech players such as Google, Microsoft, Amazon and IBM, many new startups born each year raising investments over $40.4B in 2018 (see page 88 of The AI Index 2019 Annual Report – Human-Centered AI Institute Stanford University).
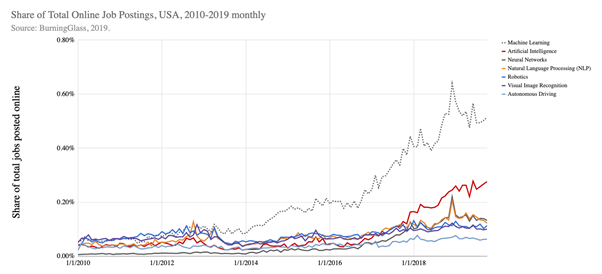
Figure 1. Different clusters of job postings from the US presented by month.
Source: The AI Index 2019 Annual Report – Human-Centered AI Institute Stanford University.
However, even if Machine Learning algorithms demonstrated high skills, most companies lack to use them appropriately as an ordinary and efficient tool to improve their business. Indeed, according to various estimates between 2017 and 2020, from 74% to 87% of Machine Learning projects and advanced analytics fail or don’t reach production (see https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/).
Such behavior can be summarized using the words of Benjamin Brewster:
“In theory, there is no difference between theory and practice, while in practice there is.”
There is a huge difference between Machine Learning Research and Applied Machine Learning. Erroneously, people mix these two concepts and think they are the same underestimating the difficulty to put a Machine Learning model into production. While Machine Learning Research, i.e., the AI publications, is concerned with developing new algorithms that solve unsolved problems, Applied Machine Learning is about applying all invented techniques to real-world problems and in such a way, they can be reliable over time in the wild world.
To be more precise, most causes of Machine Learning projects failures are:
- lack of experienced talent;
- lack of support by the leadership;
- missing data infrastructure;
- data labeling challenge;
- bad data quality;
- siloed organizations and lack of collaboration;
- technically infeasible projects;
- lack of alignment between technical and business teams.
What are the differences between standard software engineering and machine learning engineering?
A natural question that might arise is: why do so many Machine Learning projects fail? Aren’t they software like any other?
Developing a Machine Learning project is not just like developing traditional software. A Machine Learning project takes all the concepts and requirements of traditional software and extends them by adding a new dimension: data.
As shown in Figure 2, traditional programming takes as main inputs functional and nonfunctional requirements to write the program. In contrast, a Machine Learning program is based primarily on data and quality metrics. Obviously, the Machine Learning program will be integrated into a wider environment that must meet functional and non-functional requirements.
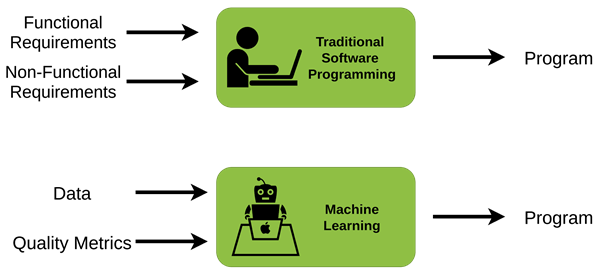
Figure 2. Differences in traditional programming and machine learning programs.
Data is no more the consequence of software usage that can be collected to analyze the product quality to improve it. Data is the raw material because Machine Learning models are built upon business requirements and data.
We can summarize the challenges of a Machine Learning Project in these few points:
- manage data;
- find the best Machine Learning algorithms that fit data;
- build the software environment to serve the model to the final users.
As we can see, only the last point is in common with traditional software development.
When does a Machine Learning project end?
As all we know, a software program development process does not end when it reaches production and is released to the final user. Programs are full of hidden bugs that arise only when used by most users in many conditions. Therefore, a program must be continuously monitored and updated to fix bugs, improve performance or refine the user interface.
Moreover, a Machine Learning program has new sources of errors or performance degradation. A Machine Learning program is dynamic; after it is put in production, new data comes every day and they can change over time, causing the model to be no more aligned with them.
For instance, let a model predicts whether a user will like certain content on a website. Over time, some users’ preferences may start to change, perhaps due to aging or because a user discovers something new. The data used for training in the past no longer reflects some user’s preferences and starts hurting the model performance rather than contributing to it.
How to deal with all these difficulties in a Machine Learning Project?
As we can see, a Machine Learning project is a complex task with new challenges but many opportunities. Much effort has been made by the Machine Learning community in the standardization of the Machine Learning Projects development. Indeed, we can talk of Machine Learning Life Cycle, and MLOps that stands for DevOps transferred to Machine Learning projects.
The stages of a Machine Learning life cycle can be grouped in two categories: research & development and production. Moreover, there is a zero-point stage that is a precondition for any project:
- Goal definition
Research and development
- Data collection & preparation
- Feature engineering
- Model training
- Model evaluation
Production
- Model deployment
- Model serving
- Model monitoring
- Model maintenance
The complete pipeline is depicted in Figure 3, solid lines show a typical flow of the project stages while dashed arrows indicate that at some stages, a decision can be made to go back in the process and either collect more data or collect different data, and revise features.
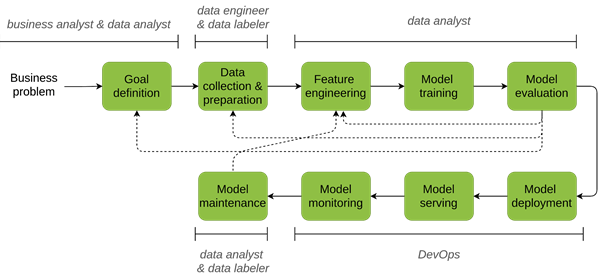
Figure 3. Machine Learning life cycle.
In the following we give a brief explanation of all the stages in the life cycle, for more details we suggest to read our other blog posts that treat each argument individually.
0. Goal definition
It is not obvious what the goal of a Machine Learning model is. Most of the time business objectives do not correspond to Machine Learning model ones. For instance, for a lending institution the objective could be to increase the loans revenues by accepting as many clients as possible without the risk of defaults. For this purpose, more than one model can be used:
- A model can be used for the advertising campaign to select the right target for each advertisement by estimating the probability a person seeing the ad will click on it;
- Another model can be used to estimate the probability the person asking for the loan will respect the payments.
Moreover, these models can have different quality metrics and criteria to assess their accuracy and other sets of Machine Learning models can compose them.
A clear objective is fundamental to evaluate the model performance correctly. A good goal allows measurable quality metrics with ranges of acceptance to decide when the model can go into production and monitor it during its life.
1. Data collection & preparation
The myth about Machine Learning is that algorithms do things automagically: give some data and to an algorithm it will learn something on that. However, a famous mantra in the Machine Learning community is “garbage in, garbage out”. If a model is trained on a bad dataset it will have low performance independently how complex the model is.
Data quality plays a central role in a Machine Learning project. Most of the effort and time must be focused on getting more data of wide variety and high quality instead of trying to squeeze the maximum out of a learning algorithm.
In this stage of the pipeline data gathered from different data sources are preprocessed by checking their consistency and correcting errors and finally, they are cast in the right format to be used by Machine Learning models.
2. Feature engineering
Raw data that come from the previous step are used to extract features the model will use to make predictions. This stage requires understanding what raw data contains and how to transform the information inside them into features. Moreover, features can be combined to create new ones or can be removed if considered not informative.
A simple example is the feature extraction from text. Since Machine Learning models work with numeric features, text data must be converted into numbers, common techniques are bag of words or text embeddings.
3. Model training
This stage of the pipeline consists on finding the right model class to solve the problem and training it on the data.
Even if model training seems to be the most important part of the pipeline it usually requires a little portion of the time in the Machine Learning project. Previous steps that work on data quality are more important.
4. Model evaluation
Development and production environments usually are very different. This means that the performance the model has on test data of the development environment will be different with production data.
Moreover, a model put in production can affect an organization business and a bad model may lead to a loss of money or a reputation deterioration.
Therefore, before the model goes in production it must be carefully evaluated, evaluation tasks may include:
- estimation of legal risks of putting the model in production;
- study of the main properties of training and production data to check see if the two domains are not too different;
- evaluate the performance of the model with data like those the model will see in production.
Recalling the first step of the pipeline, it is very important to define what the right behavior of the model is and which are the metrics to measure the model quality.
5. Model deployment
Deploying a model means to make it available to receive user inputs and to provide outputs for these inputs. Deployment can be done in different manners and mostly depends on the expected usage of the model and by the computational resources needed by it.
The main approaches to deployment are:
- static deployment: the model is a part of an installable software package and an upgrade of the model means to upgrade the entire software;
- dynamic deployment on user’s device: the model is not part of the application and it can be upgraded easily;
- dynamic deployment on the server: the model is on a server and it is accessed through HTTP requests.
In this stage of the pipeline according to the requirements the deployment approach is chosen.
For further details about model deployment, we suggest you to see other blog posts.
6. Model serving
Model serving is how the model is queried, a model can be served in either batch or on-demand mode:
- Batch mode is the best when there is a lot of input data; the model is called on the entire batch and the predictions are stored in a database. It is more resource-efficient but may require some latency to gather enough data to form a batch;
- On the other hand, with the on-demand mode the model processes a request as soon it arrives and provides the output directly to the user.
7. Model monitoring
As said before, the production environment is dynamic, leading to model’s performance degradation over time. Monitoring consists in log and analyse all the quantities of interest in order to detect when something has changed to act before it hurts the company business. The main reasons which could cause performance drops are related with the intrinsic time-varying nature of the real-world applications. The monitoring module could also provide alerts if performances drop below a fixed threshold.
This module is fundamental to understand when a model update (through model maintenance module) is required.
8. Model maintenance
The last step of the pipeline is model maintenance. This step completes the loop of the Machine Learning life cycle because it consists of running the entire pipeline again to update the model to maintain it “fresh” to the encountered production data.
Conclusion
As we can see, the Machine Learning life cycle is not as straightforward as one can think, and it requires a lot of steps and attention to guarantee that what is seen during training is the same during production.
Applied Machine Learning has very increasing trends. A lot of companies within the Machine Learning community are putting efforts into standardizing the production of Artificial Intelligence models by the operationalization of the whole life cycle we described.
This operationalization is called MLOps and is the conjunction between Machine Learning models and DevOps worlds.
Here at ML cube, we focus on making easier the transition from sporadic hand-crafted pipelines into automated and efficient Machine Learning pipelines.