
Grazie alla diffusione su larga scala dei sistemi basati su tecniche di Machine Learning e vista la loro applicazione in contesti sempre più complessi, gli esperti di questi modelli si stanno ponendo sempre più la sfida di monitorare la qualità delle predizioni effettuate da questi sistemi nel tempo.
Qual è la differenza tra un software tradizionale e uno basato su tecniche di Machine Learning?
Nei software tradizionali, colui che progetta l’algoritmo identifica una serie di operazioni che dato un input consentono di ottenere il risultato (output) desiderato. Questo non accade nel caso in cui l’algoritmo in questione sia basato su tecniche di Machine Learning, dove il comportamento del sistema non è specificato da parte del progettista, ma è dato dall’unione di due fattori: un modello matematico e un insieme di dati (tipicamente degli input a cui corrispondono degli output) che vengono utilizzati per “addestrarlo”.
Per addestramento (training in gergo tecnico) si intende una serie di operazioni tramite le quali il modello può apprendere dai dati il loro comportamento e capire come generalizzare al meglio il loro pattern comportamentale al fine di effettuare predizioni.
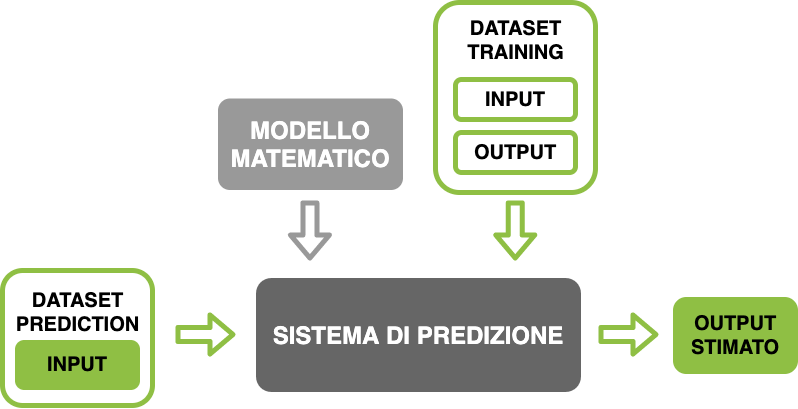
Figura 1: Lo schema di funzionamento di un modello di Machine Learning
Perché un algoritmo di Machine Learning necessita un sistema di monitoraggio?
In un modello tradizionale, il funzionamento del sistema è definito dal progettista e non è necessario testare le sue performance nel tempo (in termini di qualità delle stime effettuate) in quanto queste sono definite e statiche, dato un input.
Nei modelli di Machine Learning, come detto in precedenza, il comportamento è invece definito dai dati che verranno appresi tramite il modello indicato. Questi dati, unitamente ad un’accurata selezione del modello matematico che li generalizzerà, determinerà la qualità della stima effettuata.
Solitamente, i dati a disposizione nella fase di addestramento si dividono in almeno due insiemi, uno usato per l’addestramento (training dataset) e l’altro per la verifica del modello appreso (test dataset). Quest’ultimo dataset viene usato per verificare la bontà della scelta del modello matematico alla base dell’algoritmo.
Una volta creato il modello, è necessario monitorare la qualità delle stime che esso effettua. Questa esigenza è dovuta al fatto che allo scorrere del tempo, in un contesto mutevole (la maggior parte dei contesti applicativi reali rientrano in questa categoria), le condizioni del processo che genera i dati in ingresso possono variare alterando così la relazione che lega l’input e l’output.
In tali scenari, per identificare queste variazioni è necessario l’utilizzo di un software che consenta di monitorare le predizioni effettuate e confrontarle con i valori reali che osservati.
Come può un software di monitoraggio aiutarci a risolvere i cali di performance?
Nel caso in cui si presentino dei cali di performance sotto determinate soglie e questi cali si mantengano oltre un tempo predefinito, il software di monitoraggio notificherà che si rende necessario procedere all’aggiornamento del sistema di Machine Learning.
Si può presupporre che i dati hanno abbiano subito delle variazioni nella relazione tra input e output, questo può portare a dover effettuare due azioni:
- Riaddestramento (retrain): il modello matematico scelto in precedenza viene riaddestrato tramite un dataset che ha una distribuzione più coerente con i dati attualmente sotto analisi da parte dell’algoritmo Machine Learning.
- Cambio del modello matematico: nel caso in cui la variazione sia tanto significativa da mostrare che tramite il riaddestramento del modello le performance di stima sul test dataset (usato per verificare l’addestramento) non risultano soddisfacenti, può essere necessario effettuare una variazione al modello matematico al fine di permettere a quest’ultimo di generalizzare al meglio i nuovi dati in ingresso.

Figura 2: Esempio di andamento dell’errore di stima e possibile correzione tramite riaddestramento del modello
Conclusione
I modelli di Machine Learning riescono ormai a svolgere task molto complessi che possono avere enorme impatto per le aziende che li adottano. Queste tecniche hanno però caratteristiche a cui è necessario dare una particolare attenzione al fine di garantire livelli di performance stabili nel tempo. A tal proposito, oltre ad utilizzare tool di monitoraggio tradizionali, occorre automatizzare i processi atti a ripristinare performance ad alti livelli al fine di rendere i sistemi basati su Machine Learning sempre più affidabili e efficaci.